Tell Me Where I Am: Object-level Scene Context Prediction
CVPR 2019
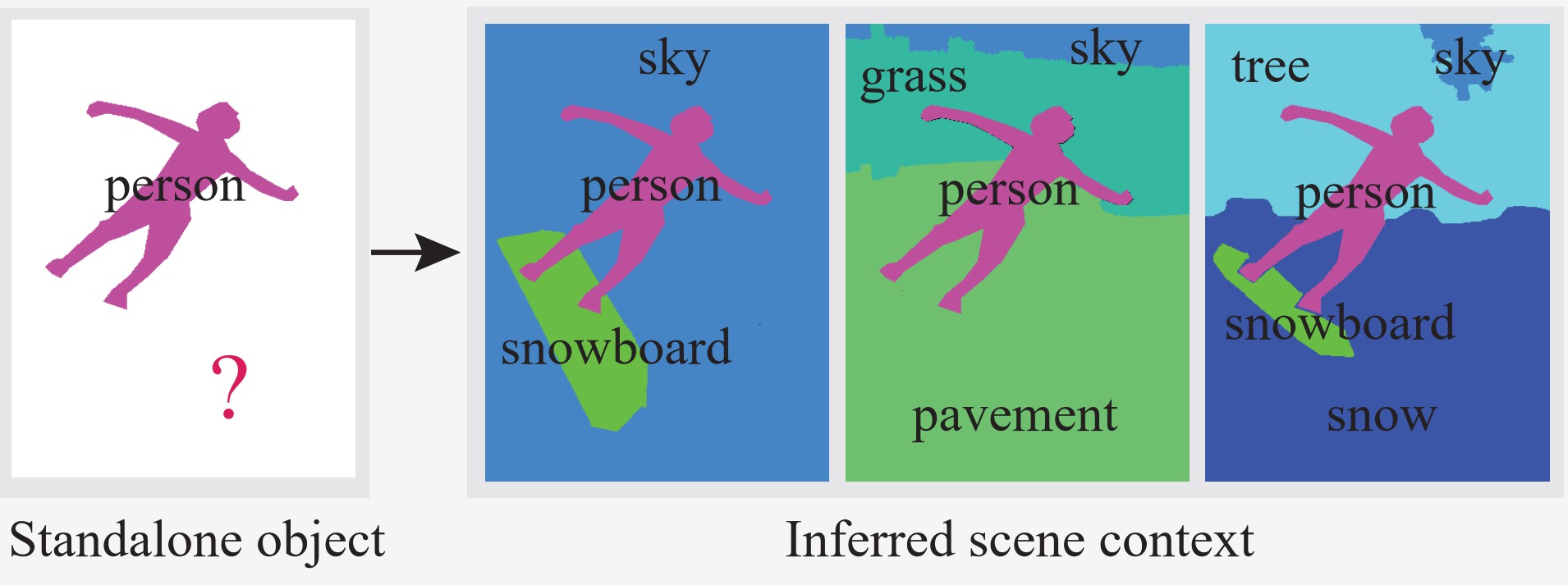
Abstract
Contextual information has been shown to be effective in helping solve various image understanding tasks. Previous works have focused on the extraction of contextual information from an image and use it to infer the properties of some object(s) in the image. In this paper, we consider an inverse problem of how to hallucinate missing contextual information from the properties of a few standalone objects. We refer to it as scene context prediction. This problem is difficult as it requires an extensive knowledge of complex and diverse relationships among different objects in natural scenes. We propose a convolutional neural network, which takes as input the properties (i.e., category, shape, and position) of a few standalone objects to predict an object-level scene layout that compactly encodes the semantics and structure of the scene context where the given objects are. Our quantitative experiments and user studies show that our model can generate more plausible scene context than the baseline approach. We demonstrate that our model allows for the synthesis of realistic scene images from just partial scene layouts and internally learns useful features for scene recognition.


Bibtex
@InProceedings{Qiao_2019_CVPR,
author = {Xiaotian Qiao, Quanlong Zheng, Ying Cao, Rynson Lau},
title = {Tell Me Where I Am: Object-level Scene Context Prediction},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2019}
}